问题总结 数学类 Nim游戏 为什么用异或可以判断先手与后手的输赢,即最后一个拿走石子的人会赢
问题1:为什么会分有先手必赢和后手必赢
问题2:如何确定每一次拿走的个数
292. Nim 游戏 - 力扣(LeetCode)
欧几里得欧拉原理 507. 完美数 - 力扣(LeetCode)
加减乘除与模运算 分享丨模运算的世界:当加减乘除遇上取模(模运算恒等式/费马小定理/组合数) - 讨论 - 力扣(LeetCode)
费马平方和定理 费马平方和定理告诉我们:
一个非负整数 c 如果能够表示为两个整数的平方和,当且仅当 c 的所有形如 4k +3 的质因子 的幂均为偶数
Q3. 平方数之和 - 力扣(LeetCode)
Floyd龟兔赛跑算法 287. 寻找重复数 - 力扣(LeetCode)
程序类 其他小问题 1.使用include的时候,<>与””的区别,<>会优先使用搜索系统目录,””会优先当前文件夹
2.换行符\n与end的区别,endl一般用于需要立即显示的信息的上面,但是\n可用于大量的数据换行,可以不着急输出,最后加一个cout<<endl刷新缓冲即可
3.c++可以连续给变量复制a=b=c=10;成立
4.在LST之中,contains的效率比count高,contains一般找到相应的元素,即可就会返回,但是count需要找完整个数组
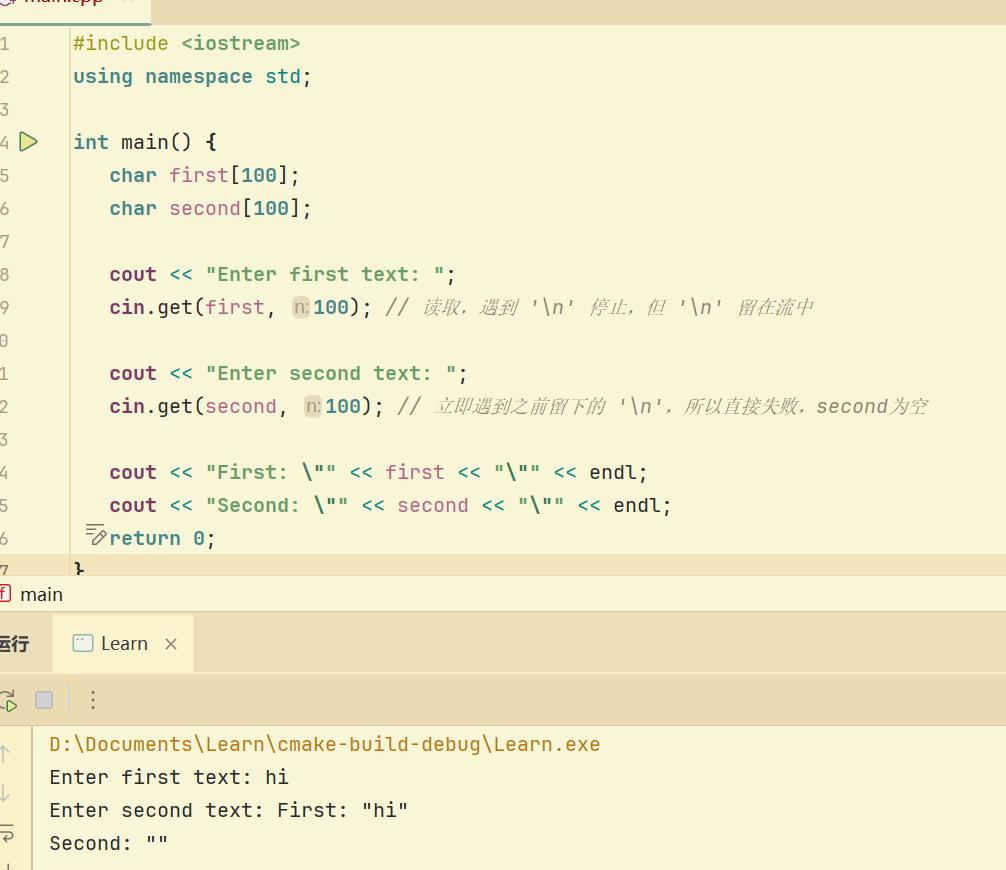
5.get与getline 的区别,getline可清理掉最后的结束换行符,但是get会保存下来,如果紧接着继续使用get们会发生错误,也就是说最后剩余的‘\n’还会被当作下一次的输入,进而导致错误
6.struct与union的区别主要在与union里面的元素只有一个有意义,但是struct里面的元素可以同时有意义、
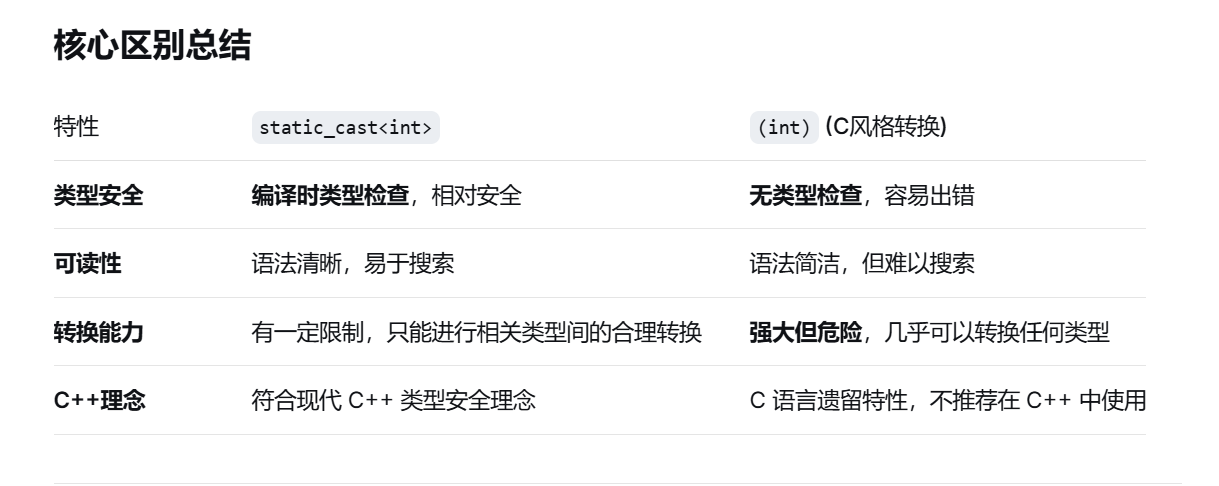
7.static_cast与(int)的区别
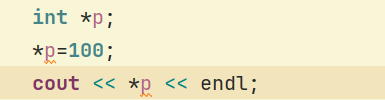
8.下面的代码,在初始化的,分配给p指向的空间可能是无效的,此时无正确的输出正确的值,是野指针
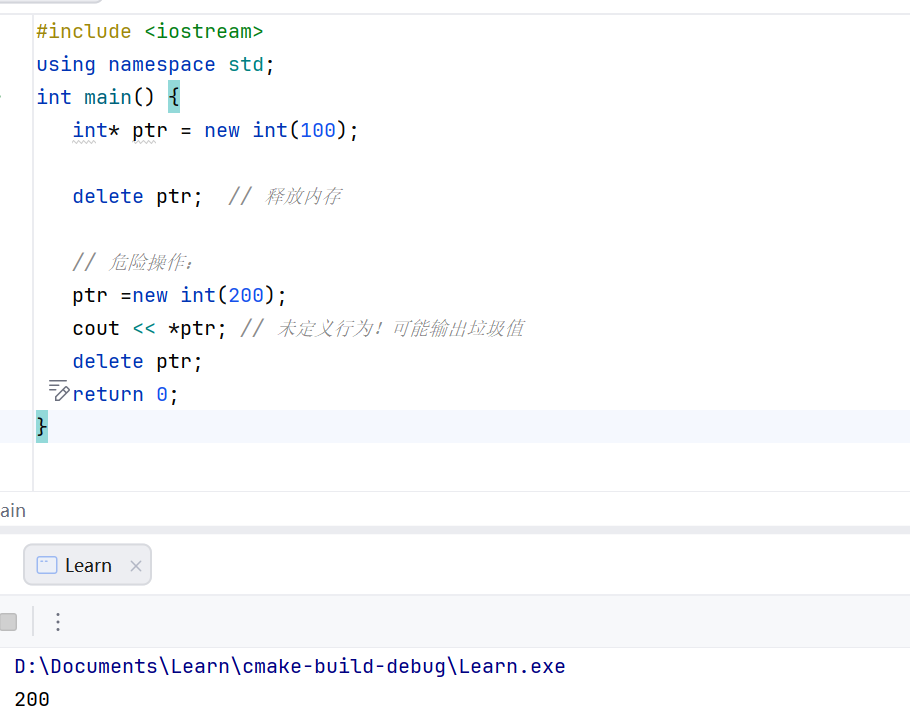
9.一个指针在被delete之后,变成了野指针,而非空指针, 此时需要重新使用的话,需要重新new一个然后指向,而野指针的定义就是为连自己指向什么类型的元素都不知道,此时赋值可能会发生上面的情况,同时注意在c++之中,允许delete空指针,但是不允许delete野指针
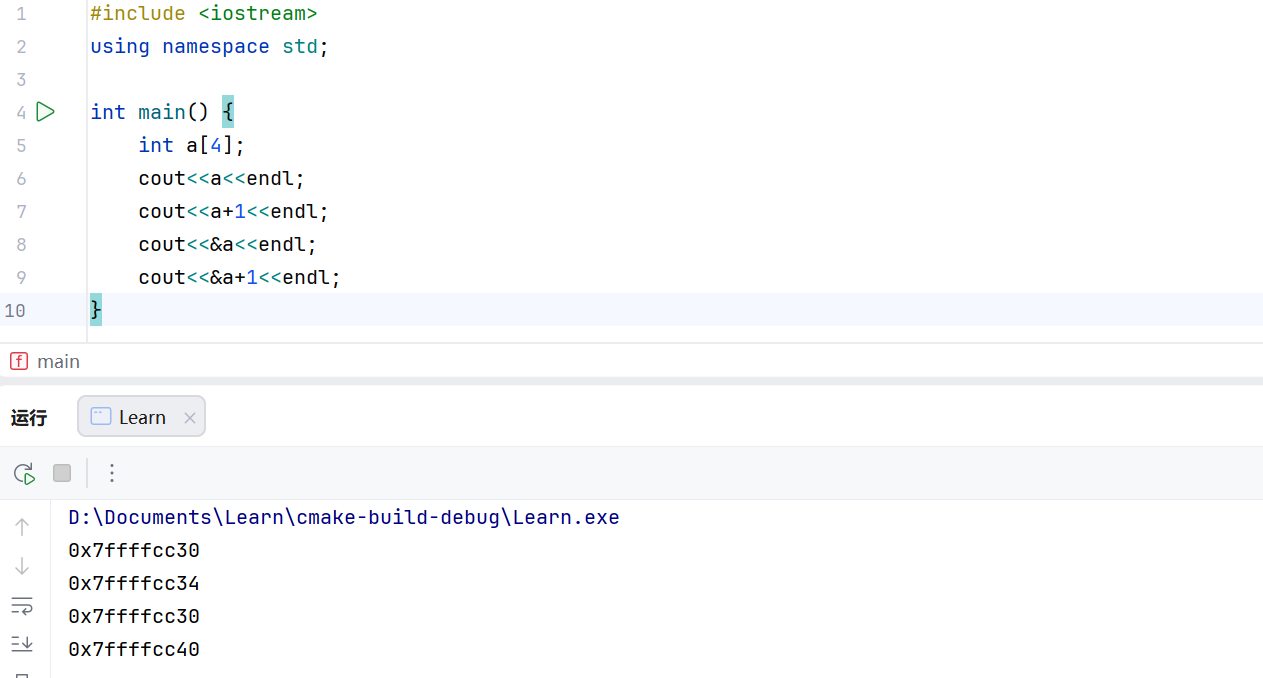
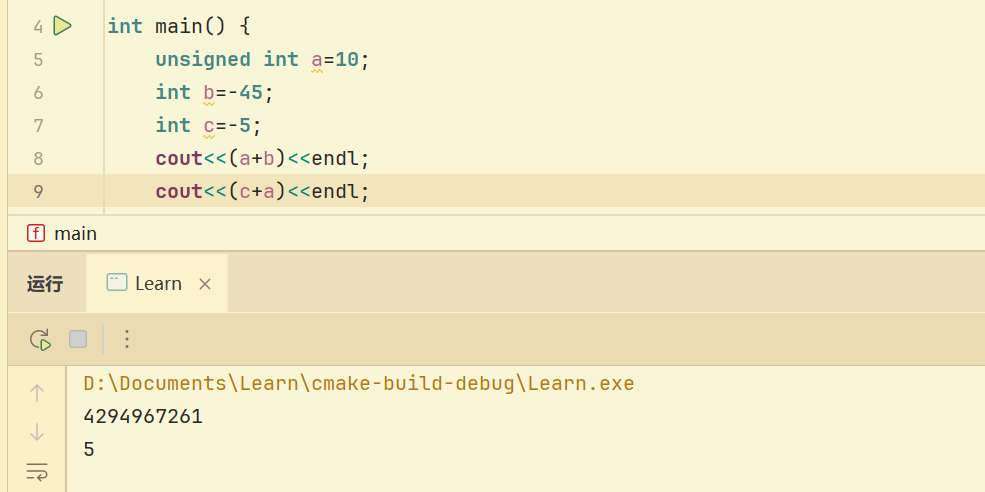
10,对于int *p=new int[10];执行p+1的操作之后,此时的p[0]实际指向了原来的p[1],请仔细看下面的输出,&a此时代表的整个数组,所以+16,换算为16进制,为+10
11.比较位置的类型
12.switch之中不能比较浮点类型的数据,其比较大值必须是一个单独的值
13.传指针与传引用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <iostream> using namespace std;void fun1 (int *a,int &b) if (!a) return ; a=new int (100 ); cout<<*a<<endl; cout<<b<<endl; } void fun2 (int &a) } int main () int a=0 ,b=10 ; fun1 (&a,a); cout<<a<<endl; }
14,传输指针与传输引用对于数组的不同点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <stdio.h> #include <iostream> using namespace std;int main () int arr[4 ] = {100 , 200 , 300 ,400 }; printf ("Accessing values:\n" ); printf ("arr[1] = %d\n" , arr[1 ]); printf ("*(arr + 1) = %d\n" , *(arr + 1 )); printf ("\nAccessing addresses:\n" ); printf ("&arr[1] = %p\n" , (void *)&arr[1 ]); printf ("arr + 1 = %p\n" , (void *)(arr + 1 )); printf ("\nUsing interchangeably:\n" ); *(arr + 2 ) = 999 ; printf ("arr[2] is now: %d\n" , arr[2 ]); cout<<&arr<<endl; cout<<&arr+1 <<endl; return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 #include <vector> #include <iostream> using namespace std;int main () int arr[12 ]={0 }; vector<int > arr1 (4 ,0 ) ; cout<<&arr<<endl; cout<<&arr+1 <<endl; cout<<&arr1<<endl; cout<<sizeof (&arr1)<<endl; cout<<&arr1+1 <<endl; }
什么是差分数组 主要用于区间更新 ,差分数组用于存储当前值与前一个值之间的差值,同时也可以很方便的恢复原数组
如何构建 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include <algorithm> #include <iostream> #include <vector> using namespace std;void createDifVec (vector<int > &arr) int pre=arr[0 ]; for (int i=1 ;i<arr.size ();++i) { int temp=arr[i]; arr[i]-=pre; pre=temp; } } void reDifVec (vector<int > &arr) for (int i=1 ;i<arr.size ();++i) { arr[i]+=arr[i-1 ]; } } int main () vector<int > arr={5 ,8 ,6 ,8 ,9 ,4 ,2 ,3 ,3 }; createDifVec (arr); cout<<"现在是差分数组的结构" <<endl; for_each(arr.begin (),arr.end (),[](int i){cout<<i;});cout<<endl; reDifVec (arr); cout<<"现在是恢复结构" <<endl; for_each(arr.begin (),arr.end (),[](int i){cout<<i;});cout<<endl; }
有什么作用 主要用于区间的更新
假设在上述的操作之上,使得下标[1-5]的值+1,但是其他值不会更改
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #include <algorithm> #include <iostream> #include <vector> using namespace std;void createDifVec (vector<int > &arr) int pre=arr[0 ]; for (int i=1 ;i<arr.size ();++i) { int temp=arr[i]; arr[i]-=pre; pre=temp; } } void reDifVec (vector<int > &arr) for (int i=1 ;i<arr.size ();++i) { arr[i]+=arr[i-1 ]; } } void intervalUpdate (vector<int > &arr,int begin,int end,int num) arr[begin]+=num; arr[end+1 ]-=num; } int main () vector<int > arr={5 ,8 ,6 ,8 ,9 ,4 ,2 ,3 ,3 }; createDifVec (arr); cout<<"现在是差分数组的结构" <<endl; for_each(arr.begin (),arr.end (),[](int i){cout<<i;});cout<<endl; intervalUpdate (arr,1 ,5 ,1 ); for_each(arr.begin (),arr.end (),[](int i){cout<<i;});cout<<endl; reDifVec (arr); for_each(arr.begin (),arr.end (),[](int i){cout<<i;}); }
进阶:二维差分 什么是单调栈 在栈之中保持其单增或者单减,找到元素左边或者右边第一个比他大或者比他小的元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 #include <iostream> using namespace std;vector<int > getNextBigValue (vector<int > nums) { stack<int > indexStack; vector<int > result (nums.size(),-1 ) ; for (int i = 0 ; i < nums.size (); ++i) { if (indexStack.empty ()) { indexStack.push (i); }else { while (!indexStack.empty ()&&nums[i]>nums[indexStack.top ()]) { result[indexStack.top ()] = nums[i]; indexStack.pop (); } indexStack.push (i); } } return result; } vector<int > getPreSmallValue (vector<int > nums) { vector<int > result (nums.size(),-1 ) ; stack<int > indexStack; for (int i=nums.size ()-1 ; i>=0 ; --i) { if (indexStack.empty ()) { indexStack.push (i); }else { while (!indexStack.empty ()&&nums[i]<nums[indexStack.top ()]) { result[indexStack.top ()] = nums[i]; indexStack.pop (); } indexStack.push (i); } } return result; } int main () vector<int > nums={2 ,1 ,2 ,4 ,3 }; vector<int > nums2 = getNextBigValue (nums); vector<int > nums3 = getPreSmallValue (nums); for_each(nums2.begin (),nums2.end (),[](int c){cout<<c;}); cout<<endl; for_each(nums3.begin (),nums3.end (),[](int c){cout<<c;}); }
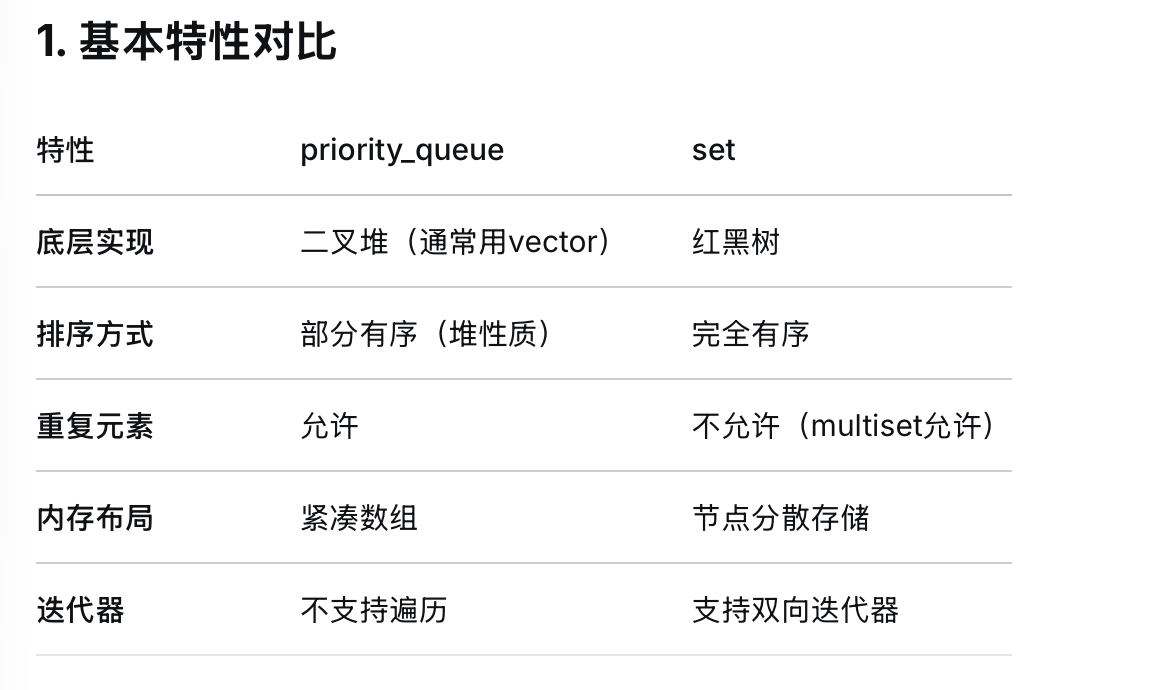
优先队列 基本特性 插入元素与删除元素均为O(logn),但是默认底层使用vector进行实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <iostream> #include <vector> #include <algorithm> #include <string> using namespace std;class Student {public : int score; explicit Student (int score) this ->score = score; } }; int main () vector<int > v{1 ,2 ,3 ,4 ,5 }; priority_queue<int > pq1 (v.begin(),v.end()) ; priority_queue<int ,vector<int >,greater<>> pq2 (v.begin (),v.end ()); cout<<"最小堆顶的元素为" <<pq2.top ()<<endl; pq2.push (0 ); pq2.pop (); auto cmp=[](int a,int b){return a<b;}; priority_queue<int ,vector<int >,decltype (cmp)> pq (cmp); auto studentCmp=[](Student &s1,Student &s2){return s1.score>s2.score;}; Student student1 (1 ) ; Student student2 (77 ) ; Student student3 (99 ) ; priority_queue<Student,vector<Student>,decltype (studentCmp)> studentPriorityQueue (studentCmp); studentPriorityQueue.push (student1); studentPriorityQueue.push (student2); studentPriorityQueue.push (student3); cout<<studentPriorityQueue.top ().score<<endl; }
注意在vector里面排序的时候,a>b是按照从大到小进行排序,但是在由于优先队列的定义是优先的关系,那么如果按照a>b进行排序的时候,此时会构成最小堆,即b堆优先度比较小,优先出去
与set的区别
请注意在删除和插入的过程之中set与priority_queue的区别
并查集 如何实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #include <iostream> #include <vector> using namespace std;class Union { vector<int > parents; vector<int > rank; int count; public : explicit Union (const int size) :count(size) { parents.resize (size); rank.resize (size,0 ); for (int i = 0 ; i < size; i++) { parents[i] = i; } } int findRoot (int i) if (parents[i] != i) { parents[i]=findRoot (parents[i]); } return parents[i]; } void unionArray (int x,int y) const int rootX = findRoot (x); const int rootY = findRoot (y); if (rootX != rootY) { if (rank[rootX] < rank[rootY]) { parents[rootX]=rootY; }else if (rank[rootY] < rank[rootX]) { parents[rootY]=rootX; }else { parents[rootX]=rootY; rank[rootY]++; } } } bool connectUnion (int x,int y) return findRoot (x) == findRoot (y); } }; int main () }
move函数 快速移动现在的元素,防止拷贝 1 2 3 4 5 6 7 8 9 10 11 12 #include <iostream> #include <vector> #include <string> int main () std::string str = "Hello, World!" ; std::string new_str = std::move (str); std::cout << "str after move: \"" << str << "\"" << std::endl; std::cout << "new_str: \"" << new_str << "\"" << std::endl; return 0 ; }
快速转移 快速转移对应的元素,容器的高速插入,容器之间的元素快速转移
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include <iostream> #include <vector> #include <algorithm> #include <string> using namespace std;int main () string str="hello world" ; string str2=move (str); cout<<str<<"-----" <<str2<<endl; str="hi" ; vector<string> v; v.push_back (move (str)); vector<string> v2={"apple" ,"ban" ,"good" ,"hi" }; vector<string> v3; move (v2.begin (),v2.begin ()+2 ,back_inserter (v3)); for_each(v2.begin (),v2.end (),[](string str){cout<<str;}); for_each(v3.begin (),v3.end (),[](string &s){cout<<s;}); }
bitset 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <iostream> using namespace std;int main () bitset<32> bits1 (-3 ) ; bitset<32> bits2 (3 ) ; cout << bits1.to_string () << endl; cout << bits1.to_ulong ()<< endl; cout << bits1.count () << endl; cout << (bits1^bits2).to_string () << endl; }
双端队列deque 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <deque> #include <iostream> using namespace std;int main () deque<int > deque={1 ,2 ,3 ,4 ,5 ,6 }; cout<<"头节点为" <<deque.front ()<<endl; cout<<"尾节点为" <<deque.back ()<<endl; cout<<"通过下标进行访问" <<deque.at (1 )<<endl; cout<<"不检查下标进行访问" <<deque[0 ]<<endl; deque.push_back (7 ); deque.push_front (0 ); deque.pop_back (); deque.pop_front (); }
C++之中的链表 单向链表forward_list 1 2 3 4 5 6 7 8 9 int main () forward_list<int > fList; fList.push_front (1 ); fList.push_front (2 ); for (int &i : fList) { cout << i << endl; } }
双向链表list 1 2 3 4 5 6 7 8 9 10 11 12 int main () list<int > lList (5 ,2 ) ; lList.push_back (1 ); lList.push_front (100 ); auto it=lList.begin (); advance (it,3 ); lList.insert (it,9 ); for (int &i : lList) { cout << i << endl; } }
C++之中的二分查找函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <set> #include <string> #include <stack> #include <iostream> using namespace std; int main() { vector<int> vec={1,2,3,4,5,6,6,7,8,9,65}; int target=8; //精准的二分查找函数 if (binary_search(vec.begin(),vec.end(),target)) { cout<<"存在对应的元素"<<endl; } //查找第一个大于等于的位置 auto lower=lower_bound(vec.begin(),vec.end(),target); cout<<*lower<<endl; //寻找第一个比此数大的数 auto upper=upper_bound(vec.begin(),vec.end(),target); cout<<*upper<<endl; //查找所有等于target的范围 auto range=equal_range(vec.begin(),vec.end(),6); //返回的迭代器是pair类型返回 cout<<(range.first-vec.begin())<<(range.second-vec.begin())<<endl; }
emplace函数 与insert的区别在于emplace是直接在参数构造对象,但是insert是首先构建参数,然后再拷贝到stl容器之中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <algorithm> #include <iostream> #include <string> #include <tuple> #include <unordered_map> #include <vector> int main () std::vector<int > v = {1 , 2 , 3 }; v.emplace_back (4 ); v.emplace (v.begin ()+1 ,100 ); std::cout<<v[1 ]<<std::endl; std::unordered_map<int ,int > hashmap={{1 ,1 }}; auto it=hashmap.emplace (2 ,2 ); std::cout<<it.second<<std::endl; hashmap.emplace_hint (hashmap.end (),3 ,2 ); return 0 ; }
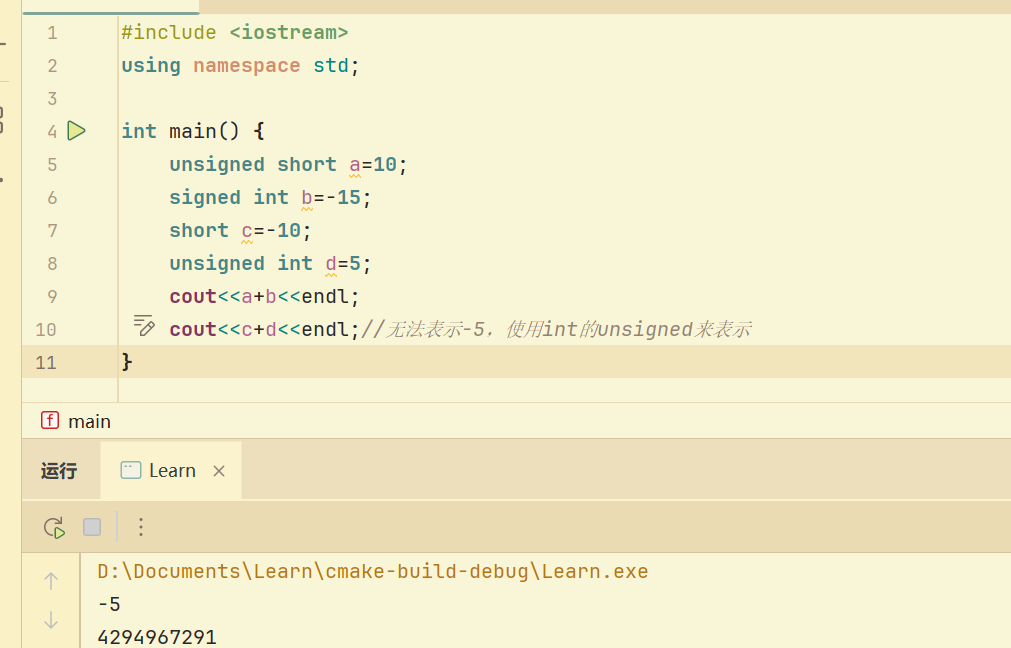
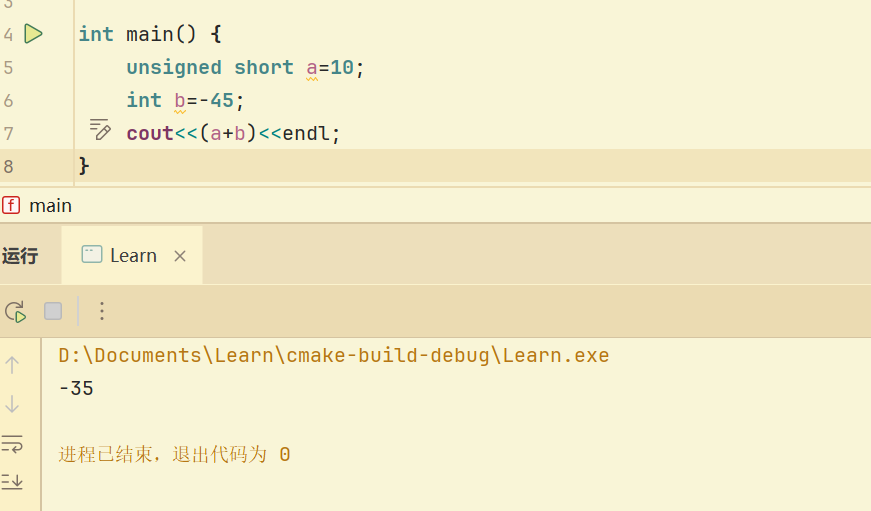
无符号数与有符号运算 首先会考虑优先级 int比short高,会转换为unsigned int进行计算
类型会首先考虑转换为无符号数
其他 当有符号数可以包括无符号数的所有范围,则按照有符号数进行运算
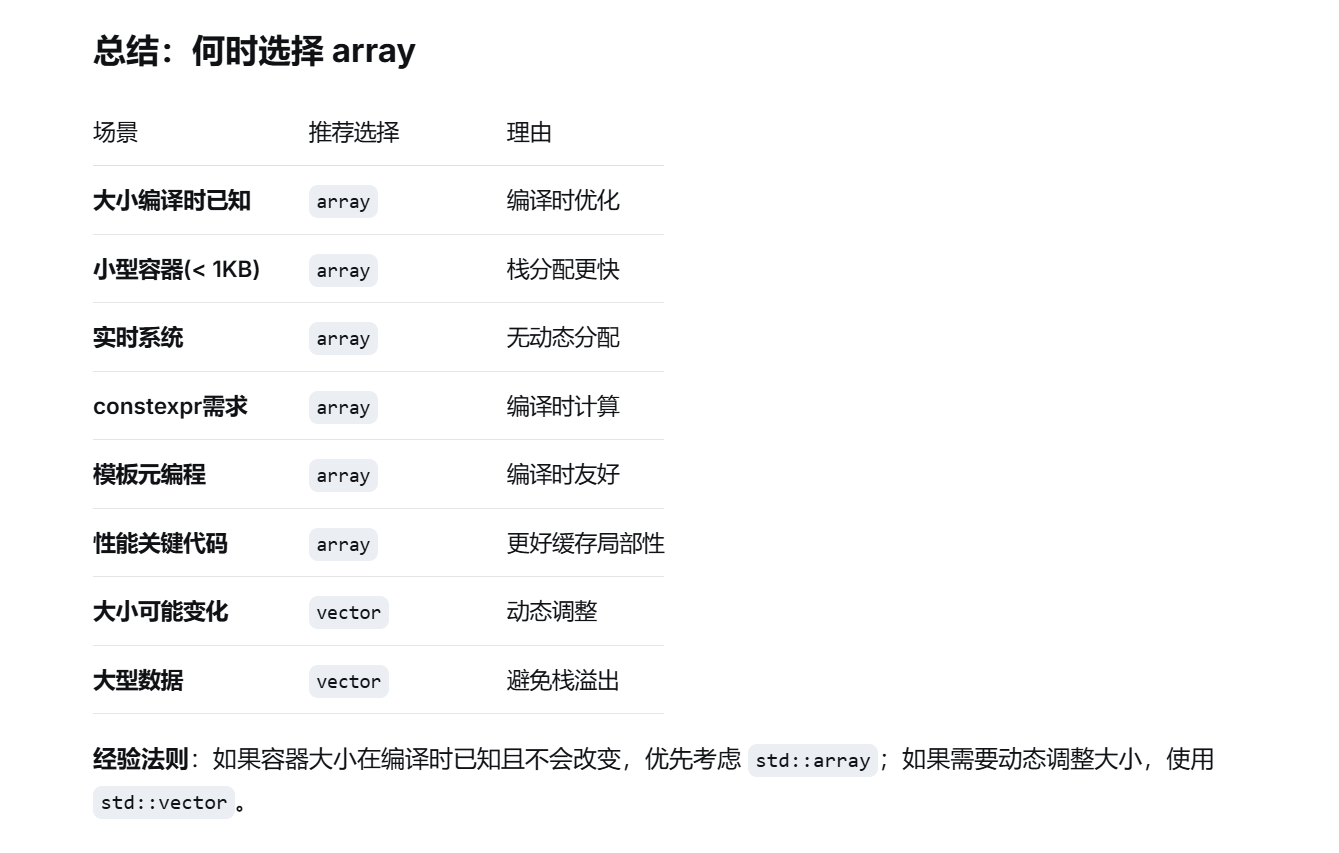
vector与array的比较 初始化的比较 首先array在初始化的时候,必须指定大小,并且之后不可变更,在其他用法方面与vector基本相同
1 2 3 4 5 6 7 8 9 10 #include <cstring> #include <iostream> #include <vector> #include <array> using namespace std;int main () array<int ,5> arr{}; vector<int > vec{}; }
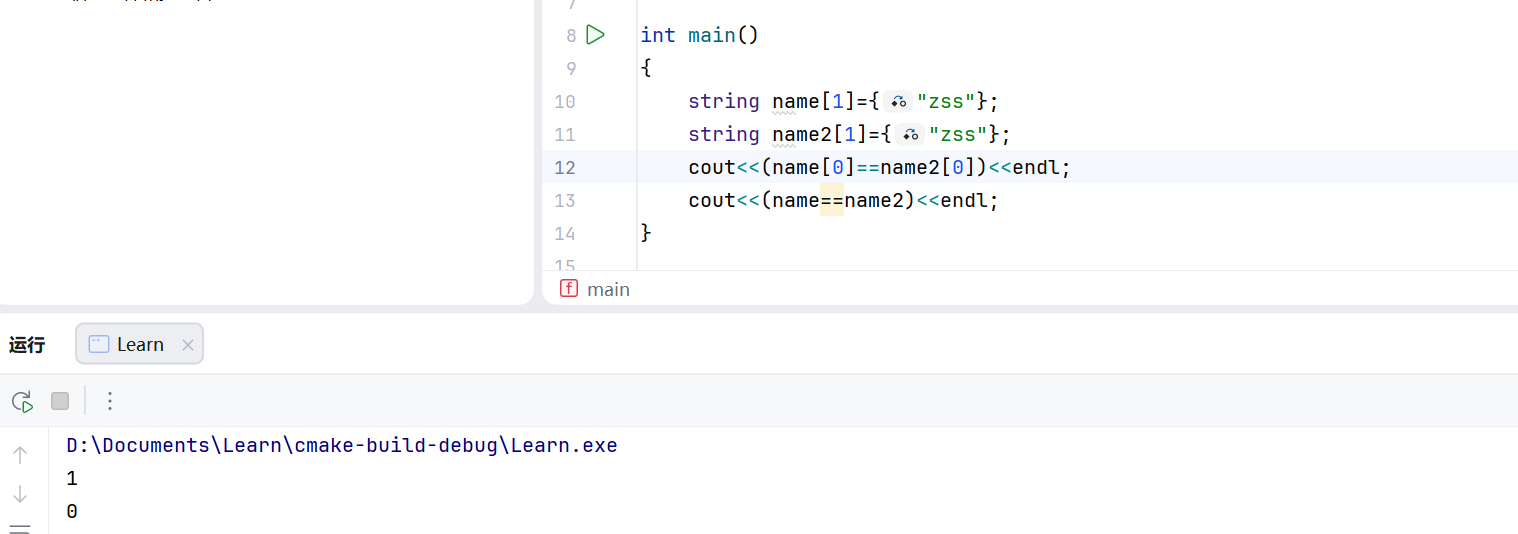
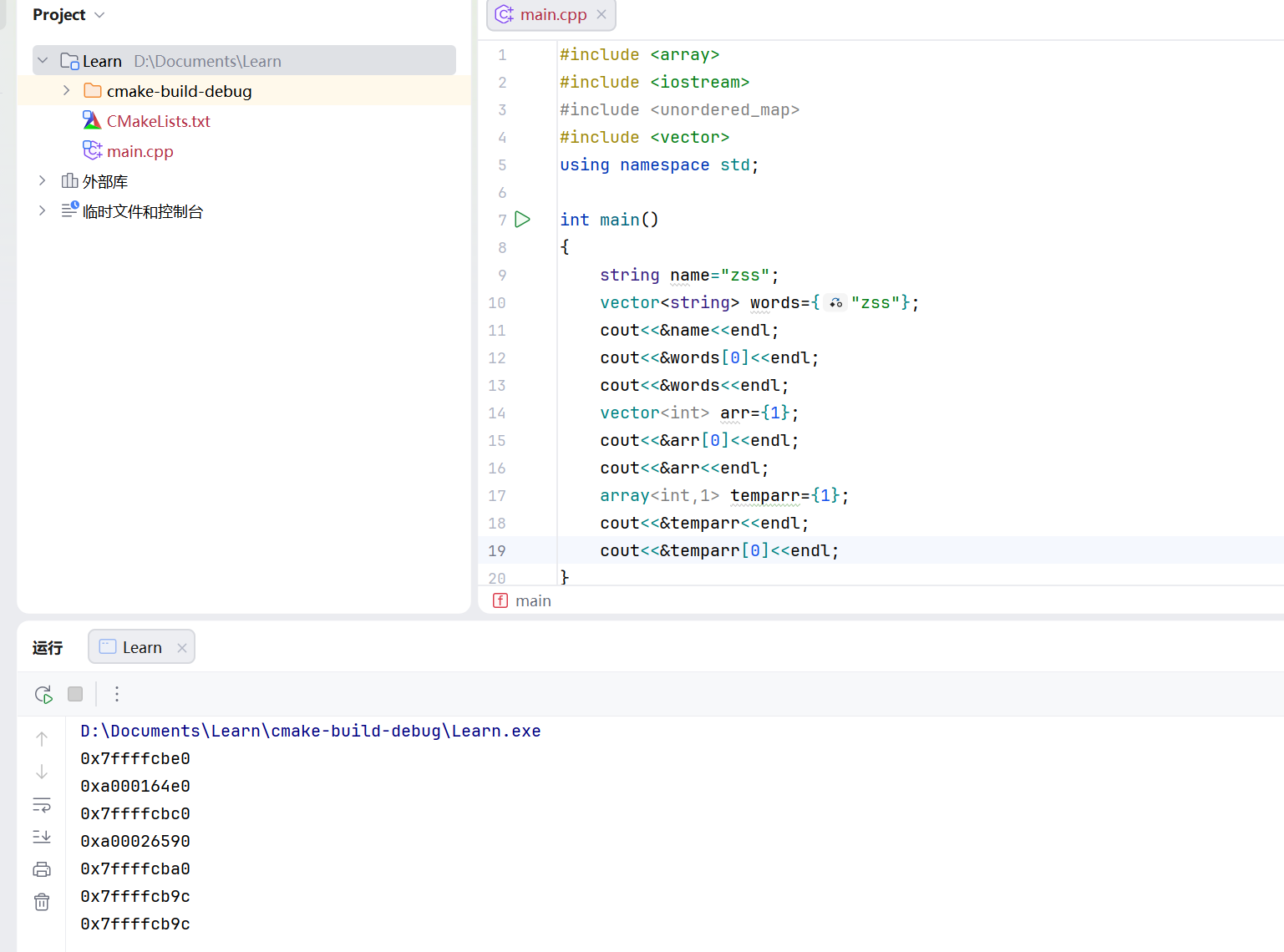
位置比较 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <array> #include <iostream> #include <unordered_map> #include <vector> using namespace std;int main () string name="zss" ; vector<string> words={"zss" }; cout<<&name<<endl; cout<<&words[0 ]<<endl; cout<<&words<<endl; vector<int > arr={1 }; cout<<&arr[0 ]<<endl; cout<<&arr<<endl; array<int ,1> temparr={1 }; cout<<&temparr<<endl; cout<<&temparr[0 ]<<endl; }
小数组 为什么推荐小数组 小数组数据量小的时候,可以存储在cpu缓存之中,此时的读取效率完全可以避免算法结构带来的差异,是对缓存友好的,在大规模的排序系统之中,子数组小到一定的长度之后,就会切换到插入排序
多长的数组可以定义为小数组 小数组应该能够舒适的放到cpu 的高速缓存(三级缓存)
枚举类 基础用法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <iostream> using namespace std;enum Weekday { MONDAY = 1 , TUESDAY, WEDNESDAY, THURSDAY = 10 , FRIDAY }; int main () Weekday day = MONDAY; cout << "Weekday: " << day << endl; return 0 ; }
枚举类的使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <iostream> using namespace std;enum class Color { RED, BLUE, GREEN }; enum class Status :int { OK, BAD, GREAT }; int main () auto col=Color::RED; cout<<static_cast <int >(col)<<endl; auto status=Status::OK; if (status==Status::OK) { cout<<"Ok" <<endl; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 #include <iostream> using namespace std;enum class Color { RED, BLUE, GREEN }; enum class Status :int { OK, BAD, GREAT }; string to_string (Color color) switch (color) { case Color::RED: return "RED" ;break ; case Color::BLUE: return "BLUE" ;break ; case Color::GREEN: return "GREEN" ;break ; default : return "UNKNOWN" ;break ; } } Color &operator ++(Color &C) { C=static_cast <Color>(static_cast <int >(C) + 1 ); return C; } int main () auto C = Color::RED; switch (C) { case Color::RED: cout<<"RED" <<endl;break ; case Color::BLUE: cout<<"BLUE" <<endl;break ; case Color::GREEN: cout<<"GREEN" <<endl;break ; } const string s = to_string (C); cout<<s<<endl; while (true ) { cout<<to_string (C)<<endl; if (C==Color::GREEN) break ; ++C; } }
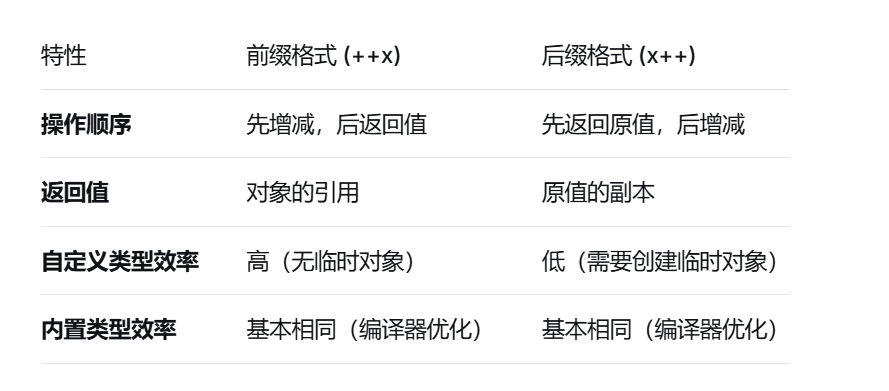
++i与i++ ++i与i++之间的区别
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <iostream> using namespace std;class Counter { public : int value; Counter (int value) : value (value) {}; Counter& operator ++() { ++value; return *this ; } Counter& operator ++(int ) { Counter tmp = *this ; ++value; return tmp; } }; int main () Counter c (0 ) ; ++c; c++; cout<<c.value<<endl; }
i++为什么不能复制自身 下面的运算之中应该old的值为5,不应该为6
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Counter {private : int value; public : Counter (int v = 0 ) : value (v) {} Counter& operator ++(int ) { Counter temp = *this ; ++value; return *this ; } }; int main () Counter c (5 ) ; Counter old = c++; return 0 ; }
运算符的重载 sizeof在函数之中失效的原因 总结一下
对于参数的使用arr[]的形式,此时传递的是指针,但是vector是将自己重新复制了一份,这样自己能够sizeof得到大小,但是指针却不可以,而下面的&arr则是指针的地址,也就是地址的地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <iostream> using namespace std;void sum_arr (long long arr[], int size) cout << "函数内 arr 地址: " << arr << endl; cout << "函数内 &arr: " << &arr << endl; cout << "sizeof(arr): " << sizeof (arr) << endl; } int main () long long cookies[7 ] = {1 ,2 ,3 ,4 ,5 ,6 ,7 }; cout << "cookies 数组大小: " << sizeof (cookies) << endl; cout << "cookies 地址: " << cookies << endl; cout << "&cookies: " << &cookies << endl; sum_arr (cookies, 7 ); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <vector> using namespace std;void change (int arr[],int size) arr[0 ]=12 ; } void change1 (vector<int > arr) arr[0 ]=12 ; } int main () int arr[12 ]={0 }; vector<int > arr1 (12 ,0 ) ; change (arr,12 ); change (arr1.data (),12 ); }
7、函数 函数与数组 指针与const 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <cstring> #include <iostream> using namespace std;int main () int * const a=new int (1 ); cout<<"a未更改之前" <<*a<<endl; *a=3 ; cout<<"a更改之后" <<*a<<endl; const int *b=new int (2 ); cout<<"b指向的地址为" <<b<<endl; b=a; cout<<"b指向的地址为" <<b<<endl; const int * const c=new int (2 ); }
int arr[]自身特性 注意int arr[]之中的arr本身就是一个指针常量,即自身指向无法被更改
1 2 3 4 5 6 7 8 9 int main () int arr[]={1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 ,10 }; int * arr2 = new int [10 ]; const int arr3[]={5 ,8 ,9 ,58 }; }
函数指针 如何设计与指定函数指针 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include <cstring> #include <iostream> #include <array> using namespace std;void fun (int a) cout << a << endl; } void fun2 (int a) cout << a << endl; } void fun3 (void (*pfun)(int )) cout<<"开始使用指针调用函数" <<endl; pfun (5 ); } int main () void (*pfun)(int ) = fun; cout<<(void *)pfun<<endl; void (*pfun2)(int ) = fun2; cout << pfun2 << endl; fun3 (pfun); void (*parr[2 ])(int )={fun,fun2}; }
8、函数探幽 内联函数 用处 常规的函数在内存之中仅仅存在一份,调用的时候,直接返回地址即可,但是需要开辟栈空间,存储其他的信息等等,但是内敛函数会将函数直接复制到对应的位置,不需要通过地址调用,但是这也会导致调用多次,会在内存之中出现多份
1 2 3 4 5 6 7 8 9 10 11 #include <vector> #include <iostream> using namespace std;inline int getS (int x) return x*x; } int main () getS (2 ); getS (4 ); }
引用变量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <vector> #include <iostream> using namespace std;int main () int a=123 ; int &b=a; cout<<&b<<endl; cout<<&a<<endl; int c=99 ; b=c; cout<<a<<" " <<b<<" " <<&a<<" " <<&b<<endl; cout<<&c<<endl; int *d=&a; cout<<d<<&a<<endl; }
为什么尽可能使用const 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <iostream> #include <string> void refcube (const double & rd) { std ::cout << rd << std ::endl ; std ::cout << "Address inside function: " << &rd << std ::endl ; } int main () { int x = 3 ; std ::cout << "Original x: " << x << std ::endl ; std ::cout << "Address of x: " << &x << std ::endl ; refcube(x); return 0 ; }
为什么在使用&的形参之中,使用const允许类型转化,但是不使用却不允许类型转换
对于非const的引用参数,我们可能会去修改他的值,如果允许自动转换的话,那么会创建临时变量,但是原来的值并不会改变,这也就是为什么使用&的时候推荐const的原因
重载 const重载的影响 注意这里是进行了值的传递,也就是复制了一份,故而是否使用const都无所谓,对原数产生不了影响,编译器认为他们是相同的
1 2 3 4 5 6 7 8 void say (const int n) std::cout << n << std::endl; } void say (int n) std::cout << n << std::endl; }
但是const如果类修饰指针或者引用,这时可以进行操作,因为是否添加指针确实会影响到原函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <filesystem> #include <iostream> void say (const int *n) std::cout <<1 <<n << std::endl; } void say (int *n) std::cout <<2 <<n << std::endl; } void say (int &n) std::cout <<3 <<n << std::endl; } void say (const int &n) std::cout <<4 <<n << std::endl; } int main () int n=10 ; say (n); int a=10 ; say (&a); }
为什么优先解释为指针
因为再这个过程之中,&a总是被优先解释为指针,而如果再只使用int &n的函数,则需要再次解引用,多了一个步骤
函数模板 基础用法 此时传入double等什么类型均可,此时如果有一个具体的swap(int,int)函数,此时会优先调用
1 2 3 4 5 6 7 8 template <typename AnyType>void Swap (AnyType &a,AnyType &b) AnyType temp; temp=a; a=b; b=temp; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #include <filesystem> #include <iostream> #include <random> template <typename AnyType>void Swap (AnyType &a,AnyType &b) std::cout<<"隐式实例化" <<std::endl; AnyType temp=a; a=b; b=temp; } template void Swap <int >(int &,int &);template <>void Swap <int *>(int *&a,int *&b){ std::cout<<"显式显式具体化" <<std::endl; for (int i=0 ;i<6 ;++i) { int temp=a[i]; a[i]=b[i]; b[i]=temp; } } int main () float a=101.1 ,b=56.2 ; Swap (a,b); std::cout<<"a=" <<a<<" b=" <<b<<std::endl; int c=1 ,d=2 ; Swap (c,d); std::cout<<"c=" <<c<<" d=" <<d<<std::endl; int e[]={1 ,2 ,3 ,4 ,5 ,6 }; int f[]={1 ,2 ,39 ,4 ,5 ,6 }; std::cout<<e<<std::endl; int *pe=e; int *pf=f; std::cout<<pe<<std::endl; Swap (pe,pf); std::cout<<e[2 ]<<std::endl; }
1.显式实例化有什么用
显式实例化可以提前生成对应的代码模板,这样再不同的代码文件之中,比如调用int类型的时候,不会重新创建一份,而是去寻找
2.如何理解显式具体化
显式具体化可以理解为对于模板类的重写,比如这里交换数组的值,可以进行具体话,进行具体方法具体分析
3.为什么再上述的代码之中,直接传入ef不可吗
c语言形式的int a[]本身就是const 类型的指针,也就是指针的指向的位置不能改变,但是其中的数值可以改变,而这里是非const,即不能进行传入目标函数之中
自己指定 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #include <iostream> using namespace std;template <typename T>T getLesser (T a,T b) cout<<"使用了模板" <<endl; return a < b ? a : b; } template <>int getLesser (int a,int b) cout<<"使用了具体的int类型" <<endl; return a < b ? a : b; } int main () int a=10 ,b=20 ; double c=10.2 ,d=5.2 ; cout<<getLesser (a,b)<<endl; cout<<getLesser (c,d)<<endl; cout<<getLesser<>(a,b)<<endl; cout<<getLesser <int >(c,d)<<endl; }
关键字decltype 基础用法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <iostream> using namespace std;template <typename T,typename U>auto add (T t,U u) ->decltype (t) return t+u; } int main () int x=10 ; double y=3.14 ; decltype (x) a=3.25 ; cout<<a<<endl; auto z=add (x,y); cout<<z<<endl; }
注意点 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <iostream> using namespace std;int main () int x=9 ; decltype (x) a=x; cout << a << endl; a=10 ; cout << x << endl; decltype ((x)) b=x; cout << b << endl; b=100 ; cout << x << endl; }
注意delctype对对于左值或者右值的作用改变
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 int x = 5 ;decltype (x) a; decltype ((x)) b = x; decltype (42 ) c; decltype ((42 )) d; int func () decltype (func ()) e; decltype ((func ())) f;
与模板函数的结合 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <iostream> using namespace std;template <typename T>auto add (T &t) ->decltype ((t)) t+=10 ; return t; } int main () int a = 10 ; cout << add <int >(a)<<endl; add <int >(a)=15 ; cout<<a; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <iostream> #include <vector> using namespace std;template <typename Container>auto get_element (Container& c, int index) -> decltype (c[index]) return c[index]; } template <typename Container>auto get_element_const (const Container& c, int index) -> decltype (c[index]) return c[index]; } int main () std::vector<int > vec{1 ,2 ,3 }; get_element (vec, 0 ) = 100 ; const std::vector<int > cvec{1 ,2 ,3 }; }
内存模型与名称空间 头文件的保护 1 2 3 4 #ifndef 标识符 #define 标识符 #endif
第一次包含 :EXAMPLE_H 未定义 → 执行 #ifndef 到 #endif 之间的代码
第二次包含 :EXAMPLE_H 已定义 → 跳过整个内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #ifndef COORDIN_H #define COORDIN_H struct Polar { double distance; double angle; }; struct Rect { double x; double y; }; Polar rect_to_polar (Rect xypos) ;void show_polar (Polar dapos) #endif
1 2 3 4 5 6 #include "coordin.h" #include "another.h" int main () }
强枚举类型 访问必须通过类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 enum Language { ENGLISH, CHINESE, MAX, }; int value = ENGLISH; int max = MAX; enum class Language : uint32_t { ENGLISH, CHINESE, MAX, }; Language lang = Language::ENGLISH;
不会隐式转换 必须经过强制类型转换来获得
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 enum Language { ENGLISH, CHINESE };enum Color { RED, BLUE };Language lang = ENGLISH; Color color = RED; if (lang == color) { } enum class Language { ENGLISH, CHINESE };enum class Color { RED, BLUE };Language lang = Language::ENGLISH; Color color = Color::RED;
可以指定底层类型 1 2 3 4 5 6 7 8 enum class Language : uint32_t { ENGLISH, CHINESE, MAX, }; static_assert (sizeof (Language) == sizeof (uint32_t ));
tuple的用处 基础用法 tuple 的作用在于可以返回不同类型的多个值,同时也可实现在stl的排序,即按照不同的类型的规则进行排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <algorithm> #include <iostream> #include <string> #include <tuple> #include <vector> int main () std::tuple<int , std::string,double > t1={789 ,"zss" ,15.69 }; std::tuple<int , std::string,double > t2={56 ,"haha" ,52.63 }; std::vector<std::tuple<int , std::string,double >> vec={t1,t2}; sort (vec.begin (), vec.end (),[](std::tuple<int , std::string,double > t1,std::tuple<int , std::string,double > t2) {return std::get <1 >(t1)<std::get <1 >(t2);}); std::cout<<"hi" <<std::endl; return 0 ; }
其他 1 2 3 4 5 6 7 #include <tuple> auto t1 = std::make_tuple (1 , "hello" );auto t2 = std::make_tuple (3.14 , 'a' );auto merged = std::tuple_cat (t1, t2);
kmp算法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 void getNext (const string &s, vector<int > &next) int j=0 ; int k=-1 ; while (j<s.length ()) { if (k==-1 ||s[j]==s[k]) { j++; k++; next[j]=k; }else { k=next[k]; } } }
未完待续
题目1590